
在cursor中配置你自己的三方key
作为一个重度vibe coding患者,我得了一种写代码就犯困的病。
为什么会有这样一个项目?
正式开始之前,先看看我的cursor支付情况



再往前就更多了,于是我在三月份暂停了一部分的支付,转为吹到了天上的claude code cli(三方key,便宜耐造,公司似乎也是这样的,狠狠地薅资本主义羊毛啊!)。
但是发现,身为一个稍微想关心一下代码质量的开发,我发现太依赖图形能力了,cli要使用多模态,我还需要知道文件路径,先复制到本地,没有浏览器工具,diff只能看片面,无法有效引用上下文甚至行间上下文,写代码像是看黑盒一样,等等问题。
遂转向codex app(不用claude desktop 是因为a社封号,搞不定),至少是拥有了一定的可视化能力。但是某些问题还是没有改变,比如付费还是很贵,比如还是没有codemap,codeindex等能力,比如基于上下文的提示词补全等。
遂放弃,改为使用codex/claude code cli + cursor,体感仍一般。那么既然cursor这么好用,有没有一种办法既能使用三方key,又能用cursor丝滑的ai嵌入能力呢?有的兄弟,有的。
总所周知,cursor支持一切 openai标准接口格式的自定义请求,setting->model->apikyes可见,在此处填入你从类openai获取的key,并修改baseUrl,即可使得除auto和claude之外的请求,都走到你的url,使用你自己的额度。
背景如上,开始实行。
通信机制
先说一下cursor得通信机制:
所以,我们的baseUrl收到消息一定是从cursor服务器来的,就需要一个https的域名,而非ip,这是必要条件,否则请求会直接截断。
cursor目前使用的仍然是早期的/v1/chat/complete端口,而非当前的/response端口,所以你自己的服务(或者三方服务)一定要支持接收/v1/chat/complete。
流式请求和响应,这个不用多说了。
基于以上三点,考虑到目前市面上的三方服务,几乎无法直接接收cursor的请求(封装了tools,message等),我直接写了一个服务用于转换,github地,仅供参考。
内容核心就是获取到cursor的请求,做拆解,归一化,合并等。代码比较简单,让ai大人看看就知道了。
设计
请求流程
编辑器 / Cursor / 自定义客户端
|
v
openai-compat-shim
- 鉴权保护
- 请求解析
- 请求体适配
- 可选字段剥离
- 可选调试抓取
- 流式透传
|
v
OpenAI 兼容上游
设计目标
- 尽可能保留原始语义信息
- 只规范化那些已知会导致兼容性问题的部分
- 除非没有更好的退路,否则不主动把结构化内容压平成纯文本
- 保持实现轻量、依赖少,方便部署到小型服务器
- 在需要时抓取完整请求/响应记录,降低生产排障成本
非目标
- 这不是完整的 OpenAI API 克隆
- 这不是会话存储系统
- 这个 shim 不会自己执行工具
- 它也不会自动修复所有上游兼容性问题
实现概览
1. 鉴权与健康检查接口
这个 shim 可以用 SHIM_API_KEY 保护 /v1/* 路径。
- 客户端发送
Authorization: Bearer <shim-key> - shim 进行校验
- shim 使用
TARGET_API_KEY转发到上游
之所以提供 /healthz 和 /v1/models,是为了让客户端在发送真实流量前先探活。
2. 请求体适配
核心适配逻辑位于 server.js 里的 adaptPayload()。
对于 /v1/chat/completions:
- 如果客户端本来就发送了原生
messages,则尽量保持不变 - 如果客户端发送的是
input,则转换为结构化messages - 保留多轮对话中的角色顺序,而不是把一切折叠成一个字符串
- 将工具定义转换为
chat.completions兼容的 function tools
对于 /v1/responses:
- 保留结构化
input - 将字符串 / 对象 / 数组形式的输入标准化为 response items,同时不破坏 tool-call 上下文
3. 保留 tool-call 上下文
这个 shim 会保留:
toolstool_choiceparallel_tool_calls- assistant 的
tool_calls - tool 结果消息
- 类似
function_call_output这样的结构化input项
这对 agent 风格客户端来说是关键能力。
4. 流式透传
只要满足以下任意一个条件,shim 就会把请求视为流式请求:
body.stream === truebody.stream_options != null- 请求头中的
Accept包含text/event-stream
启用流式后,上游流会被直接透传回客户端。
5. 调试抓取
当设置了 DEBUG_CAPTURE_DIR 时,shim 会为每个请求写入一个 JSON 文件,其中包含:
- 原始请求体
- 发往上游的适配后请求体
- 上游状态码和响应头
- 上游响应体
对于这个服务来说,这比抓网络包更有价值,因为 shim 到上游之间是 HTTPS。
我们遇到的关键 agent 问题
现象
Cursor 可以连上服务,但 agent 任务在一轮之后就停住了:
- 第一轮模型响应能返回
- 后续并没有真正进入多轮工具调用循环
- 看起来像是上游“没有 agent 能力”
一开始怀疑的方向
- 上游
gmncode.cn可能不支持 tool-calling - 上游可能不支持
responses - 上游可能会拒绝强制
tool_choice
这些猜测在某些边缘情况下部分成立,但它们并不是主要阻塞点。
真正的根因
shim 里有两个主要兼容性问题。
根因 1:与工具相关的字段被错误剥离了
早期版本会删除这些字段:
toolstool_choiceparallel_tool_calls
光这一点就足以让 agent 行为失效。
根因 2:多轮结构化 input 被压平成了单条用户消息
这是更深层的问题。
Cursor 当时把请求发到了 /v1/chat/completions,但请求体使用的是带有多轮结构化对话的 input:
- system 指令
- 之前的 user 轮次
- 之前的 assistant 轮次
- 当前 user 轮次
- 工具定义
旧版 shim 会把整个 input 数组拼成一大段文本,再包装成:
[
{
"role": "user",
"content": "huge flattened text..."
}
]
这会直接破坏对话结构:
- 角色边界丢失
- 之前 assistant 轮次不再是 assistant 轮次
- tool call 连续性丢失
- 模型看到的已不再是真正的 agent 对话
第三个兼容性问题
Cursor 的工具定义当时也不是 chat.completions 最偏好的格式。
真实客户端流量里出现过这样的 tools:
{
"type": "function",
"name": "Shell",
"description": "...",
"parameters": { ... }
}
甚至还有:
{
"type": "custom",
"name": "ApplyPatch",
"description": "..."
}
对于 chat/completions,当工具被转换成下面这种形式时,上游表现会更稳定:
{
"type": "function",
"function": {
"name": "Shell",
"description": "...",
"parameters": { ... }
}
}
我们是怎么修复的
修复 1:默认保留 agent 相关字段
shim 现在默认不再删除与工具相关的字段。
取而代之的是,它支持通过下面的环境变量配置需要剥离的顶层字段:
STRIP_FIELDS
默认值:
STRIP_FIELDS=audio
修复 2:把 input 转换为真正的多轮 messages
对于 /v1/chat/completions,shim 现在会把 input 数组转换为保留角色语义的 chat messages。
例如:
role: system/user/assistant的项会保留为各自独立的消息function_call项会变成 assistant 的tool_callsfunction_call_output项会变成role: tool消息input_text和output_text内容片段会被标准化为 chat 文本片段
这正是让 agent 行为恢复正常的关键改动。
修复 3:把工具定义标准化为 chat completions 格式
shim 现在会将下面这些工具:
- 顶层
function工具 custom工具
转换成 chat.completions 风格的 function tool 定义。
这样上游就能识别出真正可调用的工具,而不是把它们当成不透明元数据。
修复 4:增加请求/响应抓取
我们加入了 DEBUG_CAPTURE_DIR,这样就能在生产环境直接查看真实流量,而不是靠猜。
这让我们可以对比:
- Cursor 实际发送了什么
- shim 实际适配成了什么
- 上游实际返回了什么
整个排查过程也因此从猜测变成了基于证据的分析。
我们验证过什么
我们直接对 https://gmncode.cn/v1 验证了上游行为。
观测结果如下:
- 普通
/v1/chat/completions可以工作 - 带 tools 的
/v1/chat/completions可以工作 /v1/chat/completions可以返回tool_calls/v1/chat/completions可以接受工具结果后的后续消息/v1/responses可以在第一轮返回 function calls- 在我们的测试中,
/v1/responses配合previous_response_id的后续调用不够稳定 - 某些形态下的强制工具选择,比正常的
tool_choice: "auto"更不稳定
因此,对当前这套部署来说,最可靠的路径是:
- 让 Cursor 流量继续走
/v1/chat/completions - 把混合
input请求体适配成结构化messages - 把 tools 标准化成
chat.completions的 function-tool 格式
配置
复制示例文件并填入你自己的值:
cp .env.example .env
环境变量:
PORT: 监听端口TARGET_BASE_URL: 上游基础 URL,例如https://your-provider.example/v1TARGET_API_KEY: 上游服务商的 keySHIM_API_KEY: 编辑器 / 客户端访问这个 shim 时使用的 keyDEFAULT_MODEL:/v1/models暴露的默认回退模型名STRIP_FIELDS: 代理前需要剥离的顶层请求字段,多个值用逗号分隔DEBUG_CAPTURE_DIR: 保存完整请求/响应抓取文件的目录NODE_USE_ENV_PROXY: 设为1后,Node.js 会让内置http/https请求遵循环境变量代理HTTP_PROXY: 上游出站 HTTP 代理,例如http://127.0.0.1:7892HTTPS_PROXY: 上游出站 HTTPS 代理,例如http://127.0.0.1:7892NO_PROXY: 不走代理的地址白名单,例如127.0.0.1,localhost
示例:
PORT=8787
TARGET_BASE_URL=https://your-openai-compatible-provider.example/v1
TARGET_API_KEY=sk-xxxx
SHIM_API_KEY=replace-with-your-own-secret
DEFAULT_MODEL=gpt-5.4
STRIP_FIELDS=audio
DEBUG_CAPTURE_DIR=
NODE_USE_ENV_PROXY=1
HTTP_PROXY=http://127.0.0.1:7892
HTTPS_PROXY=http://127.0.0.1:7892
NO_PROXY=127.0.0.1,localhost
本地运行
export $(grep -v '^#' .env | xargs)
npm start
使用 PM2 运行
export $(grep -v '^#' .env | xargs)
pm2 start ecosystem.config.cjs
pm2 save
PM2 配置同样会透传这些变量:
STRIP_FIELDSDEBUG_CAPTURE_DIRNODE_USE_ENV_PROXYHTTP_PROXYHTTPS_PROXYNO_PROXY
服务器通过机场代理访问上游
如果你的服务器直连 gmncode.cn 很慢,但本机还好,最稳的办法不是改协议层,而是让服务器的出站请求先走本地代理。
推荐做法:
- 服务器运行
mihomocore,而不是运行Clash Verge Rev图形客户端 mihomo使用订阅拉取节点- 本地暴露一个代理端口,例如
127.0.0.1:7892 - shim 通过
NODE_USE_ENV_PROXY=1+HTTP_PROXY/HTTPS_PROXY访问上游
原因:
Clash Verge Rev是桌面 GUI 客户端,不适合无头服务器- 当前这个项目使用的是 Node 内置
http/https - 从 Node.js
v22.21.0开始,可以通过NODE_USE_ENV_PROXY=1让内置网络请求遵循环境变量代理
相关参考:
- Node.js 企业网络配置文档:https://nodejs.org/en/learn/http/enterprise-network-configuration
- Mihomo service 文档:https://wiki.metacubex.one/en/startup/service/
- Mihomo proxy-providers 文档:https://wiki.metacubex.one/en/config/proxy-providers/
1. 准备 Mihomo 配置
仓库内提供了一个样板文件:
把其中的订阅地址替换成你自己的订阅链接。
2. 验证代理是否真的加速
在服务器上先验证 mihomo 本地代理本身能正常访问上游:
curl -x http://127.0.0.1:7892 -I https://gmncode.cn/
如果这条请求比直连明显更稳或更快,再让 shim 挂上代理。
3. 让 shim 走本地代理
把 .env 配成类似这样:
PORT=8787
TARGET_BASE_URL=https://gmncode.cn/v1
TARGET_API_KEY=sk-xxxx
SHIM_API_KEY=replace-with-your-own-secret
DEFAULT_MODEL=gpt-5.4
STRIP_FIELDS=audio
DEBUG_CAPTURE_DIR=
NODE_USE_ENV_PROXY=1
HTTP_PROXY=http://127.0.0.1:7892
HTTPS_PROXY=http://127.0.0.1:7892
NO_PROXY=127.0.0.1,localhost
4. systemd 方式部署
仓库内提供了一个 systemd 样板:
要点:
After=mihomo.service,确保代理 core 先起来EnvironmentFile=/etc/openai-compat-shim.envNODE_USE_ENV_PROXY=1HTTP_PROXY/HTTPS_PROXY指向本地mihomo端口
请求示例
健康检查
curl http://127.0.0.1:8787/healthz
模型列表
curl http://127.0.0.1:8787/v1/models \
-H "Authorization: Bearer replace-with-your-own-secret"
基础 chat completion
curl http://127.0.0.1:8787/v1/chat/completions \
-H "Content-Type: application/json" \
-H "Authorization: Bearer replace-with-your-own-secret" \
-d '{
"model": "gpt-5.4",
"messages": [
{ "role": "user", "content": "say hello" }
]
}'
流式 chat completion
curl -N http://127.0.0.1:8787/v1/chat/completions \
-H "Content-Type: application/json" \
-H "Authorization: Bearer replace-with-your-own-secret" \
-d '{
"model": "gpt-5.4",
"stream": true,
"messages": [
{ "role": "user", "content": "reply with ok only" }
]
}'
Cursor 风格的混合 input + chat completions
这是最关键的兼容性场景:
curl http://127.0.0.1:8787/v1/chat/completions \
-H "Content-Type: application/json" \
-H "Authorization: Bearer replace-with-your-own-secret" \
-d '{
"model": "gpt-5.4",
"input": [
{ "role": "system", "content": "You are a coding agent." },
{
"role": "user",
"content": [
{ "type": "input_text", "text": "Use the calc tool to compute 2+2." }
]
}
],
"tools": [
{
"type": "function",
"name": "calc",
"description": "Evaluate arithmetic",
"parameters": {
"type": "object",
"properties": {
"expr": { "type": "string" }
},
"required": ["expr"]
}
}
]
}'
调试与故障排查
1. 开启抓取
DEBUG_CAPTURE_DIR=/path/to/captures
重启之后,每个请求都会生成一个 JSON 文件,包含:
originalBodyadaptedPayloadupstreamStatusupstreamHeadersupstreamBody
2. 先看什么
如果 agent 行为异常,优先对比这些点:
- 客户端有没有发送
tools? - 客户端发送的是
messages还是input? - 经过适配后,shim 是否还保留了多角色结构?
- assistant 输出里有没有
tool_calls? - 上游返回的是
finish_reason: "tool_calls"还是finish_reason: "stop"?
3. 常见失败模式
现象:模型直接回答,没有调用工具
检查:
- tools 是否被剥离了?
- tools 是否被标准化成了正确格式?
- 多轮
input是否被压成了一条 user 字符串?
现象:第一轮能跑,第二轮失败
检查:
- 后续工具结果消息是否被保留为
role: tool function_call_output是否被正确转换- 上游路径到底是
/chat/completions还是/responses
现象:本地正常,生产环境异常
检查:
- PM2 环境变量是否正确
- 重启时是否使用了
--update-env DEBUG_CAPTURE_DIR是否可写- Nginx 是否对流式响应做了缓冲或超时截断
4. 推荐的调试流程
- 开启
DEBUG_CAPTURE_DIR - 复现一次问题
- 打开最新的抓取文件
- 对比
originalBody和adaptedPayload - 确认问题属于哪一类:
- 客户端请求格式
- shim 适配逻辑
- 上游兼容性
- 服务器出站网络质量
5. 网络层排查顺序
如果服务器上表现明显比本机差,优先排查网络层,不要先怀疑 agent 协议。
顺序如下:
- 服务器直连
gmncode.cn测一次 - 服务器通过
mihomo本地代理再测一次 - 对比
time_total、握手耗时和首包耗时 - 只有在网络层差异不明显时,才继续看 shim 抓包
示例:
curl -o /dev/null -s -w 'direct dns=%{time_namelookup} connect=%{time_connect} tls=%{time_appconnect} ttfb=%{time_starttransfer} total=%{time_total}\n' https://gmncode.cn/v1/models
curl -o /dev/null -s -x http://127.0.0.1:7892 -w 'proxy dns=%{time_namelookup} connect=%{time_connect} tls=%{time_appconnect} ttfb=%{time_starttransfer} total=%{time_total}\n' https://gmncode.cn/v1/models
部署拓扑
典型生产部署如下:
- 公网 HTTPS 域名由 Nginx 提供入口
- Nginx 反向代理到
127.0.0.1:$PORT - 编辑器 / 客户端指向
https://your-domain.example/v1 - 由 PM2 保持 shim 常驻
当前已知限制
- 这个 shim 本身不持久化对话状态
- 它依赖客户端主动发送正确的历史轮次
- 不同服务商下,
responses配合previous_response_id的续接可能仍然不稳定 - 一些服务商对
tool_choice的格式比其他服务商更严格
维护说明
如果新的客户端集成出现问题,不要一开始就靠猜。
请按顺序用抓取结果回答这几个问题:
- 客户端实际发了什么?
- shim 实际转发了什么?
- 上游实际返回了什么?
实际排查中,大多数问题都会落在这几类:
- 请求格式不匹配
- 工具 schema 不匹配
- 多轮上下文被压平
- 上游对特定字段更敏感
这正是 Cursor agent 问题里发生过的事,而真正的修复方式,是保留结构,而不是把结构“简化”掉。
尚未解决的问题
目前发现,cursor对于多模态,无法直接使用baseUrl替代,其他所有的tools均可以使用。故只要不主动塞图给他,而是让他基于code的任务,和直接的cursor体验无任何区别。非要用多模态怎么办?反正都是要开pro的,直接换claude模型啊!反正额度不用白不用。
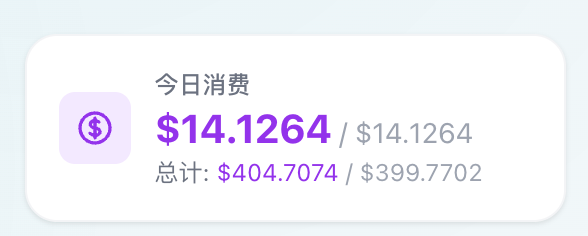
服务受限于你的三方key,比较看上游脸色,但是用几十块换两千块,我个人还是乐意的。下面是我十天的使用量,至少不用担心钱突然不见了。
具体的实施方案,我在仓库readme有详细说明,希望能帮助到你我的朋友~(馕言文语气)