
浏览器渲染机制的理解
有关浏览器渲染机制的学习
浏览器渲染原理
先看看这个图:
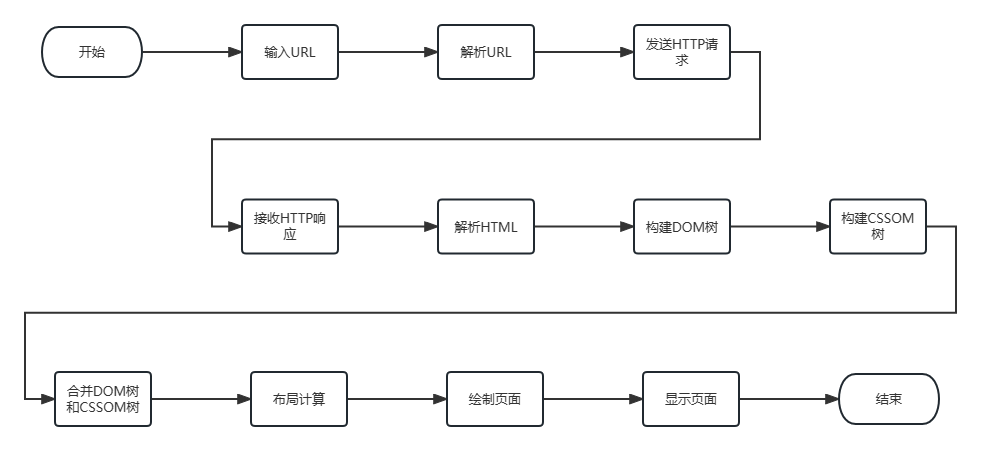
接下来我们从每一个节点来分析浏览器在做什么。
输入url,解析url
没啥可说的,浏览器接收一个url,从该url获取到html文本,这个过程涉及到更多的http通信知识,这篇我们学习浏览器渲染就不说了,当然,俺现在也说不清楚。
解析html
从这段开始,就是我们要说的主要内容了。 渲染的第一步就是解析html,在解析htm的过程开始之前,浏览器会开辟出一个与构建线程,该线程用于提前下载html中链接的css和js文件。
在解析过程中,遇到css就执行css,遇到js就执行js。但是!如果遇到css时css并没有下载完成,则会跳过该css,继续解析之后的内容。但是遇到js时,如果js没有下载好,就会暂停当前的解析, 转而等待js下载完成。这是因为js代码有可能会修改到dom或者cssom,必须等待js执行。
构建dom树
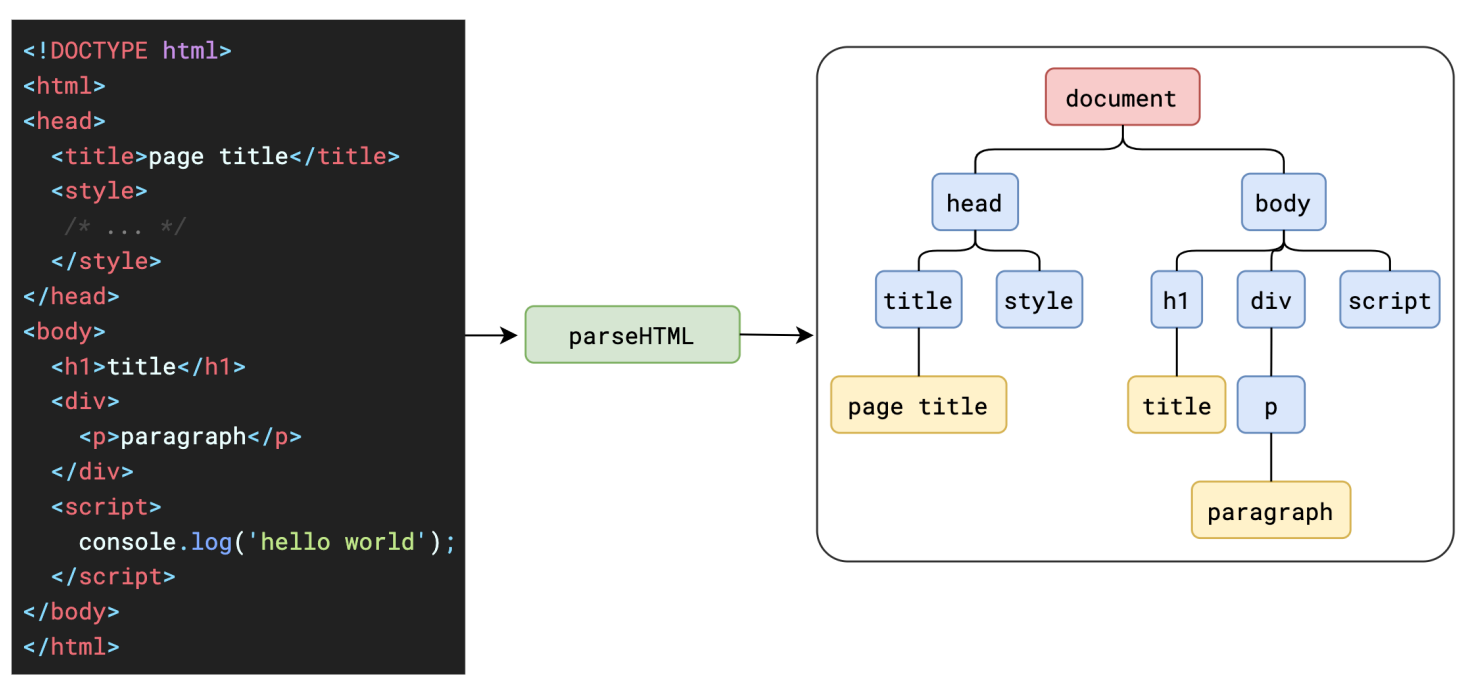
在解析html的过程中,主线程会读取到html中的各种节点,包括html,head,body,div,p,a...这些内容将被构建为一个树形结构,根节点就是document,每个子节点就是一个 c++对象。形如下图:
构建cssom树
在解析html的过程中,当预构建线程下载完毕css文件后,或者本就没有外部的css文件,主线程会读取css内容,生成一个与dom树相同结构的cssom树,每个子节点同样是一个c++对象。
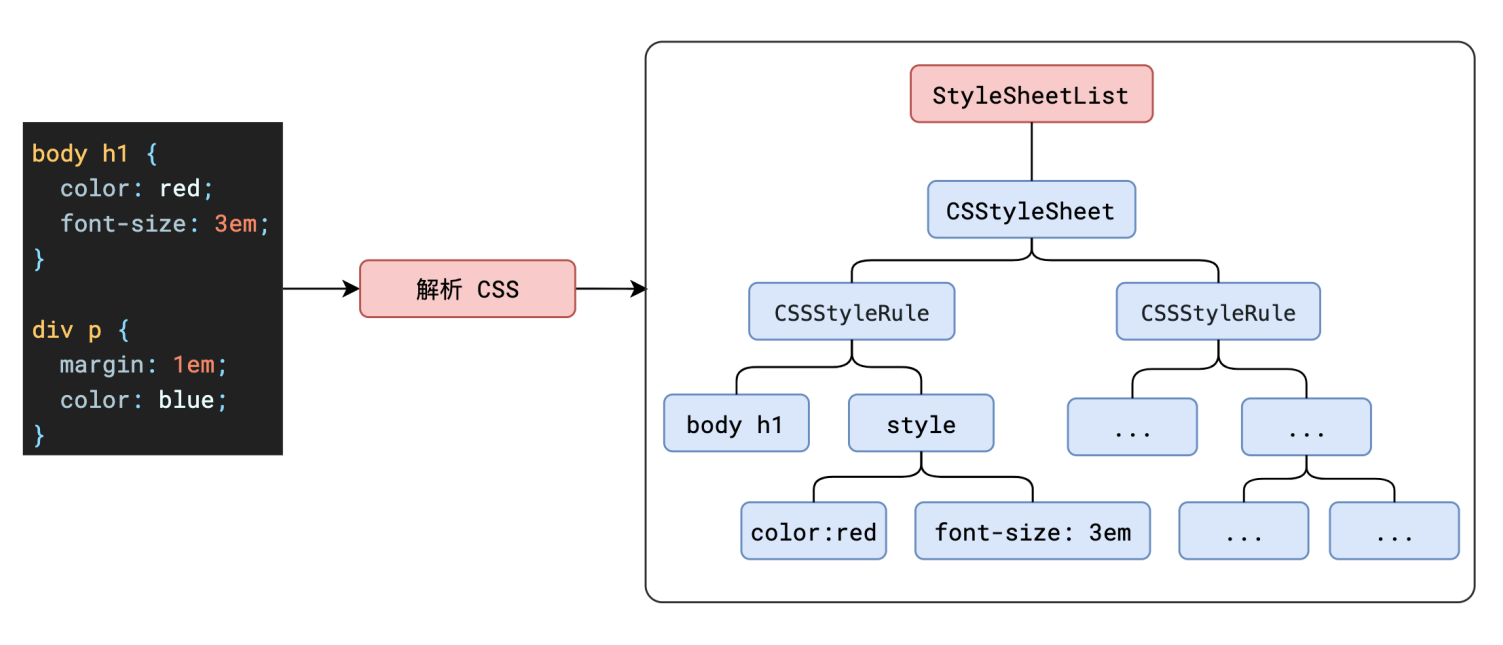
浏览器的默认样式、内部样式、外部样式、行内样式均会包含在 CSSOM 树中。
计算样式、获取布局
在获取到cssom和dom后,主线程将两者合并,启动样式计算
在浏览器的控制台中,如果有关注过style的话,会发现style存在一列名为"已计算"或"computed"
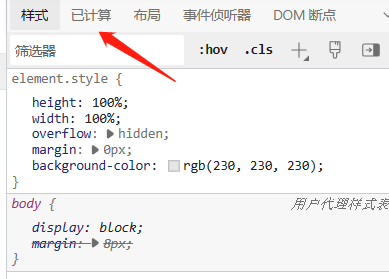
在这个位置,会发现每个元素都有着所有理论存在的css属性,这些属性是开发者并没有书写的内容,比如我们写了一个div,设置其color:red。 但是在计算属性中,所以div会存在的css属性都会经过浏览器的计算(通过dom和cssom)获得一个默认值。
盒模型的理解
在之前的一些知识内容中,我们通常会错误的认为,一个盒子包含了一些元素,那么这个盒子就是子元素的包含块。事实上并不是的,在最新的w3c标准中, 对包含块有了一些新的解释。感兴趣的可以前往看看。 包含块决定了生成布局树时的元素定位!
dom树和布局树并不是同种事物,通常,在dom树中会解析出display:none的节点,但是在布局树中并不会出现该节点。在dom树中并不会解析出伪元素节点,但是在布局树中,伪元素也被认为是节点之一,因为需要布局。 此外,还有一些行盒,块盒等都不会在dom中体现,反而在布局中却需要体现。
通常来说,布局树意味着已经生成了每个节点的几何信息。
分层渲染
在布局计算完毕,获取到布局树之后,浏览器会使用一系列复杂的策略,对获取到的布局树进行分层。
分层是为了在节点被修改后更快的重新渲染,而非整体页面再渲染一次。在google浏览器中,可以通过控制台的3d视图清晰的看到当前页面的分层情况,比如:
浏览器会有自己的策略决定该页面是否需要分层,需要分多少层。但是有一些css属性能够影响到分层策略(请注意,我使用的是影响而不是决定)。比如熟知的z-index以及will-change属性。
绘制图形
绘制图形并不代表着整个流程已经完成了,它仅仅是主线程对每个分层生成了一个绘制策略-可以认为是形成了一个对计算机的指令几何,告诉接下来的工作需要如何执行。
- 主线程对每个分层都形成一个独立的绘制指令集,用于描述该分层需要如何绘制。
- 将这些指令集分发给合成线程,接下来的工作将从主线程转移到合成线程。
- 合成线程对每个图层进行分块,可能是像素基点,也可能是屏幕的一部分,取决于浏览器策略。
- 分块活动是一个数量非常多的任务集合,所以合成线程将会从线程池取出一些线程进行分块工作。
光栅化
光栅化是将html的描述性信息转化为像素信息的过程,事实上,不止是浏览器,任何有关图像输出的地方都存在光栅化。
在浏览器中,绘制线程通过分块后,获得了每个块区的每个像素点的色彩值,这个矩阵形式的色彩值集合将发送给光栅线程,该线程通过一些与gpu交互的手段,比如gpu加速等获得图像信息(像素数据)。
这个像素数据事实上仍然不是我们所看到的图像信息,它是一块块的位图(确定了每个像素点的绝对位置和色彩信息)
画
合成线程拿到每个层、每个块的位图后,生成一个个「指引(quad)」信息。
指引会标识出每个位图应该画到屏幕的哪个位置,以及会考虑到旋转、缩放等变形。
变形发生在合成线程,与渲染主线程无关,这就是transform效率高的本质原因。
合成线程会把 quad 提交给 GPU 进程,由 GPU 进程产生系统调用,提交给 GPU 硬件,完成最终的屏幕成像。